
基于測井成巖相識別的多維自適應深度聚類模型
中文題目: 基于測井成巖相識別的多維自適應深度聚類模型
論文題目:Multidimensional Adaptive Deep Clustering for Intelligent Diagenetic Facies Logging Recognition
錄用期刊/會議:SPE Journal (中科院大類三區)
原文DOI:https://doi.org/10.2118/224431-PA
見刊時間:2025.4.9
作者列表:
1) 張麗英 中國石油大學(北京)人工智能學院 公共教學中心
2) 賀靜宇 中國石油大學(北京)人工智能學院 計算機技術 碩士 22
3) 陳潞夢 中國石油大學(北京)人工智能學院 計算機技術 碩士 23
4) 毛治國 中國石油勘探開發研究院
5) 石兵波 中國石油勘探開發研究院
摘要:
測井成巖相識別是利用測井數據來識別巖石在成巖作用過程中形成的不同成巖相,主流的有監督深度學習方法依賴大量標注數據,但成巖相的標注樣本稀有且昂貴。因此本文面向測井成巖相識別的無監督學習任務,提出了無監督學習的多維自適應深度聚類模型(Multi-dimensional Adaptive Deep Clustering,MADC),實現高維數據、復雜地質環境下的測井成巖相類別的自動識別。該模型創新性地結合卷積注意力模塊(Convolutional AttenTion,CAT)和門控循環單元(GRU)混合模型的自編碼器技術,從屬性和時空多個維度全面挖掘測井曲線特征,并引入Metropolis-Hastings算法實現自適應學習成巖相類別數,為成巖相識別提供了一種更高效、經濟的解決方案。在鄂爾多斯盆地的6個真實場景的測井數據集上進行了大量實驗,驗證了MADELINE方法的有效性與優越性。實驗結果表明,MADELINE在測井成巖相識別任務中的性能顯著優于現有的聚類模型。MADELINE模型為石油勘探開發提供了低成本和快速的成巖相識別方法。該研究對儲層質量評價、含油性預測及勘探開發決策具有實際應用價值。
背景與動機:
成巖相是表征儲集層性質、類型和優劣的標志,成巖相識別對高效勘探和開發致密砂巖氣藏至關重要。目前成巖相識別的研究集中于使用依賴標簽的監督學習方法,然而成巖相標簽的制作過程需借助精密儀器且依賴專家標注,成本高昂,這極大限制了監督學習方法的泛化應用。因此,成巖相識別領域亟需一種高效且具備自適應能力的無監督學習方法。為了解決這些問題,本研究提出了一種基于無監督學習的深度聚類模型MADELINE。
設計與實現:
MADELINE模型由非對稱自編碼器模塊和自適應簇數量學習模塊組成。非對稱自編碼器模塊ASIA包括由卷積注意力和門控循環單元組成的編碼器以及由卷積注意力模塊組成的解碼器,其中,卷積注意力模塊用于提取關鍵屬性特征,從而捕捉測井屬性之間的相互依賴信息,門控循環單元用于處理測井數據的時空特征,特別是測井數據沿深度方向的相關性。這種設計充分結合測井數據的特性,有效促進了模型提取高質量的測井特征表示。自適應簇數量學習模塊ACME由兩個多層感知機組成,使用軟聚類標簽結合Metropolis-Hastings算法自適應學習聚類簇數。
模型結構如圖1所示,編碼器從高維測井數據中提取低維特征,解碼器通過重構損失優化特征質量,聚類模塊則根據特征分布自適應劃分成巖相類型。
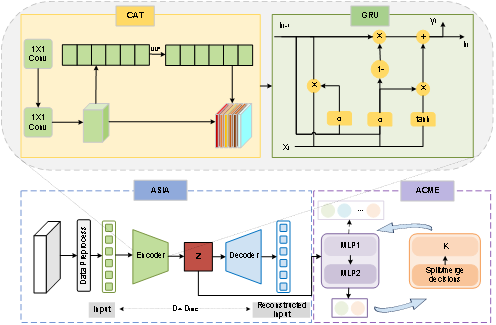
圖1 MADELINE模型結構圖
實驗結果與分析:
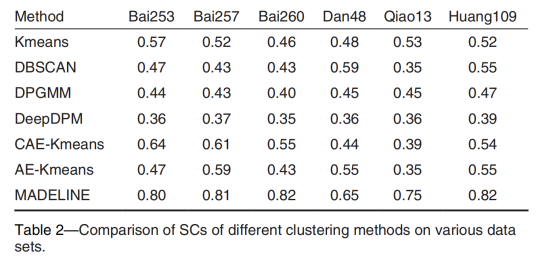
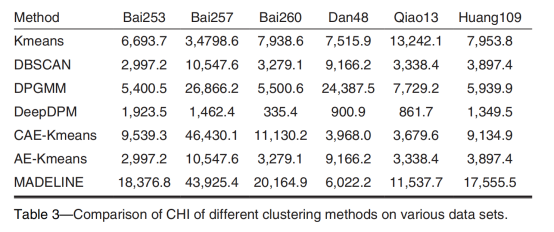
為了驗證所提方法的有效性,將MADELINE與三種經典聚類方法和四種前沿聚類方法進行比較。三種標準方法為Kmeans、DBSCAN和DPGMM。四種深度聚類方法包括DeepDPM、CAE-KMeans和AE-KMeans。MADELINE分別在輪廓系數(SC)和方差比準則(CHI)均取得最優性能。對比模型相比,本文提出的方法在SC指標上比性能最好的對比模型高8.94%。
利用t-SNE將DeepDPM、AE-KMeans、CAE-KMeans、MADC對Bai257數據集的聚類結果可視化,如圖2所示,不同的成巖相類型用不同顏色表示,虛線橢圓表示每類數據在95%置信區間內的分布范圍。圖3.4d為MADELINE方法的聚類結果,相比其它方法的結果,其類別之間的分界更加明確,且離群點更少。這表明MADELINE在處理測井數據時具有更好的聚類性能,能夠更有效地將不同類型成巖相區分開。
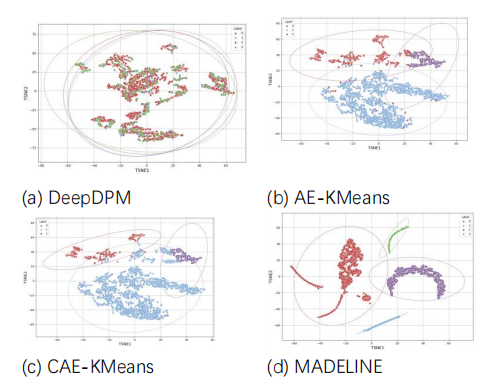
圖2 特征可視化
結論:
MADELINE模型通過非對稱自編碼器和自適應聚類模塊,有效解決了測井數據分布差異和標簽稀缺的問題,在成巖相識別任務中展現出優越性能。該方法為油氣勘探提供了低成本、高效率的解決方案,具有顯著的實際應用價值。未來可探索端到端特征提取與聚類集成,以及半監督學習優化,進一步提升模型精度和穩健性。
作者簡介:
張麗英,講師。博士,中國石油大學(北京)人工智能學院碩士生導師。主要研究方向:圖機器學習、時空數據挖掘、油氣人工智能及應用。
聯系方式:lyzhang1980@cup.edu.cn