
聯邦強化狀態的近似行為度量表征方法
中文題目:聯邦強化狀態的近似行為度量表征方法
論文題目:Approximated Behavioral Metric-based State Projection for Federated Reinforcement Learning
錄用期刊/會議:34th International Joint Conference on Artificial Intelligence (CCF A / CAA A)
錄用/見刊時間:2025年4月28日
作者列表:
1)郭增霞 中國石油大學(北京)人工智能學院 計算機科學與技術專業 碩24
2)安博暉 中國石油大學(北京)人工智能學院 計算機科學與技術專業 碩24
3)呂仲琪 中國石油大學(北京)人工智能學院 計算機系教師
文章簡介:
本文提出了一種聯邦強化學習方法,通過共享一種近似行為度量狀態投影函數的參數,提升強化學習性能并保護隱私安全。
摘要:
聯邦強化學習通常共享加密的本地狀態或策略信息,使各客戶端在保護隱私的前提下協作學習。本研究提出了FedRAG框架,各客戶端學習基于近似行為度量的狀態投影函數,并在中心服務器上聚合該投影函數參數。該方法有望提升學習性能并保護隱私。在DeepMind Control Suite上進行的大量實驗,證明該方法有效。
背景與動機:
聯邦強化學習面臨環境異構所帶來的策略偏移挑戰,同時需保護隱私。已有研究發現,基于行為度量的表征學習,通過學習狀態投影函數,可以加速強化學習過程,并提高策略泛化能力。該投影函數對策略學習至關重要,同時不會暴露任務相關的敏感信息。
設計與實現:
FedRAG在每個客戶端本地學習基于近似行為度量的狀態投影函數,服務器則通過聚合這些本地函數構建全局狀態投影函數,綜合了不同環境的動態特性與獎勵信息。在訓練過程中,客戶端定期用全局函數替換本地函數,并通過L2正則項保持與全局函數的一致性,從而提升本地策略的魯棒性與適應性。
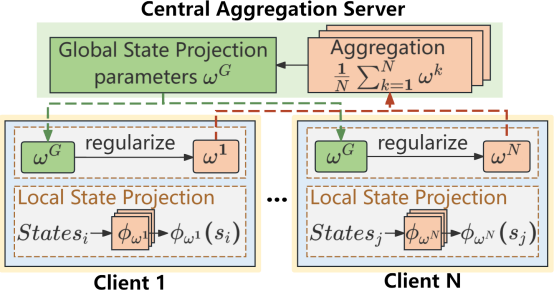
圖1 FedRAG框架圖
主要內容:
FedRAG通過共享狀態投影函數的參數來優化本地策略,旨在最大化累積獎勵和熵。
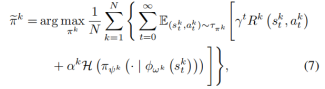
圖2 問題定義公式
減少近似差距(RAG)的行為度量方式,衡量了狀態間的預測獎勵和狀態轉移差異。
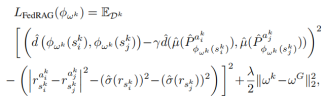
圖3 狀態投影損失函數
FedRAG算法共享狀態投影函數參數,使各客戶端在保持自身本地訓練優勢的同時,融入全局特性。

圖4 FedRAG算法框架
針對半誠實攻擊者和貝葉斯推斷攻擊,證明所上傳的狀態投影函數參數,不直接與私有數據相關。
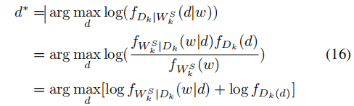
圖5 抗攻擊有效性分析
實驗結果及分析:
在DeepMind Control Suite 基準測試平臺下的cartpole-swing任務中,將FedRAG與基線方法(單機RAG、FeSAC、FedAvg)進行性能比較,證明其有效性和魯棒性。
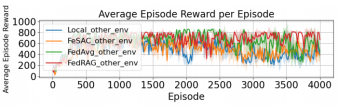
圖6 FedRAG與基線性能比較
增加正則化參數,提高了局部全局一致性,當參數為0.001時性能最好,其后過大的參數值,使局部訓練過于接近初始點而減少訓練性能。
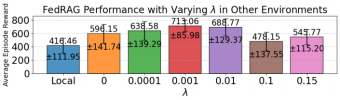
圖7 不同參數值下FedRAG性能
在其它任務中,FedRAG(與單機RAG比較)都表現出很好的性能。
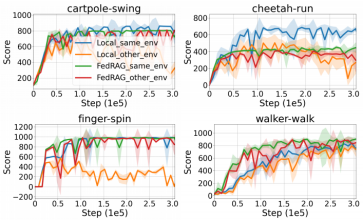
圖8 FedRAG在不同任務下性能
隨著client數量和環境異質性增加,FedRAG的性能保持穩定(與FedAvg比較)。
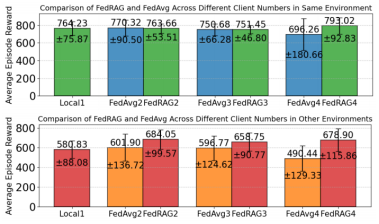
圖9 FedRAG隨客戶端數量和環境異構性能變化
結論:
分享基于近似行為度量的狀態投影函數參數,可以提高聯邦強化學習性能并保護隱私。所提出的FedRAG框架,引入了一種基于近似行為度量的狀態投影函數,并開發了聯邦算法。實驗證明所提方法的有效性。
作者簡介:
郭增霞,碩士研究生,研究方向為聯邦學習。安博暉,碩士研究生,研究方向為表示學習。呂仲琪,副教授,人工智能學院計算機系系主任,研究領域包括知識發現與數據挖掘、油氣人工智能等。
通訊作者簡介:
呂仲琪,副教授,人工智能學院計算機系系主任,研究領域包括知識發現與數據挖掘、油氣人工智能等,研究成果被廣泛應用于騰訊、微軟、深交所、中海油、中石化等企業。