
科研動(dòng)態(tài)
預(yù)訓(xùn)練擴(kuò)散模型的無記憶增量學(xué)習(xí)
中文題目:預(yù)訓(xùn)練擴(kuò)散模型的無記憶增量學(xué)習(xí)
論文題目:Memory-free Incremental Learning on Pretrained Diffusion Model
錄用期刊/會(huì)議:CCDC2025(CAA A類會(huì)議)
錄用時(shí)間:2025.1.9
作者列表:
1)張豪豪 中國(guó)石油大學(xué)(北京)人工智能學(xué)院 控制科學(xué)與工程 研22級(jí)
2)劉建偉 中國(guó)石油大學(xué)(北京)人工智能學(xué)院 自動(dòng)化系 教師
摘要:
1)我們提出了一種新穎的框架,該框架利用預(yù)訓(xùn)練的擴(kuò)散模型進(jìn)行生成性重放,消除了對(duì)內(nèi)存緩沖區(qū)的需要,同時(shí)解決了有關(guān)內(nèi)存開銷和數(shù)據(jù)隱私的問題。
2)我們引入LCM模塊來加速數(shù)據(jù)生成,顯著降低計(jì)算成本。
3)我們?cè)谌齻€(gè)基準(zhǔn)數(shù)據(jù)集CIFAR-10、CIFAR-100和Mini-ImageNet上的實(shí)驗(yàn)表明,我們的方法始終優(yōu)于基準(zhǔn)方法。
主要內(nèi)容:
圖1描繪了增量學(xué)習(xí)框架,其結(jié)合了三個(gè)不同的數(shù)據(jù)源以促進(jìn)模型訓(xùn)練。傳統(tǒng)的經(jīng)驗(yàn)重放(ER)方法涉及通過將舊樣本存儲(chǔ)在內(nèi)存緩沖區(qū)中并定期重放它們來訓(xùn)練模型。另一方面,DGR利用生成模型(例如或GAN)來創(chuàng)建用于生成重放的合成樣本,這需要生成訓(xùn)練和分類網(wǎng)絡(luò)的同時(shí)訓(xùn)練。與DGR相比,本文利用預(yù)訓(xùn)練的擴(kuò)散模型作為再生重放的來源,使我們能夠只關(guān)注分類網(wǎng)絡(luò)。重放方法通過重放保存在內(nèi)存緩沖區(qū)中的早期任務(wù)的圖像選擇來增強(qiáng)模型性能。為了保持公平,我們的生成模型為每個(gè)任務(wù)生成相同數(shù)量的圖像,與基于重放的方法中使用的數(shù)量相匹配。當(dāng)一個(gè)新的任務(wù)被引入時(shí),我們應(yīng)用生成重放策略從先前的任務(wù)中隨機(jī)選擇標(biāo)簽信息的子集,并基于提示生成相應(yīng)的圖像樣本。這些生成的圖像隨后與來自當(dāng)前任務(wù)的小批量圖像相結(jié)合,并輸入到網(wǎng)絡(luò)中進(jìn)行訓(xùn)練。
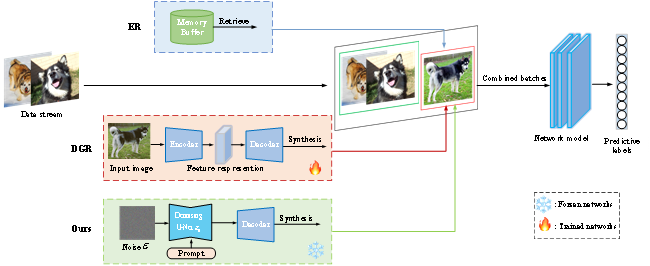
圖1 本文的模型總體框架
結(jié)論:
提出一種基于擴(kuò)散的在線課堂增量學(xué)習(xí)生成重放方法。為了解決與數(shù)據(jù)隱私和內(nèi)存限制相關(guān)的問題,我們的方法消除了在訓(xùn)練期間存儲(chǔ)示例圖像的需要。此外,考慮到用有限的數(shù)據(jù)從零開始訓(xùn)練生成模型的挑戰(zhàn),特別是在在線增量學(xué)習(xí)中,我們建議利用預(yù)訓(xùn)練擴(kuò)散模型的能力來生成圖像。為了加速傳統(tǒng)擴(kuò)散模型的采樣階段,我們?cè)跐撛诳臻g中制定正向和反向擴(kuò)散過程,進(jìn)一步利用潛在一致性模型(LCMs)來加速采樣。重要的是,所提出的方法提供了很強(qiáng)的兼容性,并可以與各種增量學(xué)習(xí)策略相結(jié)合。我們的方法在三個(gè)基準(zhǔn)數(shù)據(jù)集上進(jìn)行了評(píng)估,實(shí)驗(yàn)結(jié)果表明,它明顯優(yōu)于先前的深度生成重放基準(zhǔn)方法。
作者簡(jiǎn)介:
劉建偉,教師。