
基于加性注意力的圖像融合提示的文本到圖像擴散模型
中文題目:基于加性注意力的圖像融合提示的文本到圖像擴散模型
論文題目:Text-to-Image Diffusion Models via Additive Attention-based Image Fusion Prompts
錄用期刊/會議:CCDC2025(CAA A類會議)
錄用時間:2025.2.9
作者列表:
1)刁國文 中國石油大學(北京)人工智能學院 控制科學與工程 研22級
2)劉建偉 中國石油大學(北京)人工智能學院 自動化系 教師
摘要:
在傳統(tǒng)的文本到圖像模型的微調(diào)過程中,直接對模型進行全參數(shù)微調(diào)不僅計算成本高昂、難以實現(xiàn),還容易導致過擬合,削弱模型的泛化能力,嚴重時甚至會引發(fā)災(zāi)難性遺忘。為解決這些問題,適配器微調(diào)作為一種通過在預訓練模型中引入少量額外參數(shù)來實現(xiàn)高效微調(diào)的輕量級方案,逐漸成為文本到圖像模型微調(diào)的主流方法之一。本文首先設(shè)計了一個基于加性注意力的圖像融合模塊,使適配器能夠同時注入兩張圖像提示進行訓練,增強了模型從圖像提示中提取特征的能力。其次,利用穩(wěn)定擴散模型中U-Net網(wǎng)絡(luò)的跳躍連接,能夠在減少適配器參數(shù)量的同時,有效傳遞圖像提示信息到U-Net網(wǎng)絡(luò)的上采樣塊,確保了生成的圖像和圖像提示的對齊。實驗結(jié)果表明,我們的方法在保持適配器原有優(yōu)勢的基礎(chǔ)上,進一步提升了適配器的性能。
背景與動機:
在傳統(tǒng)的文本到圖像模型的微調(diào)過程中,直接對模型進行全參數(shù)微調(diào)不僅計算成本高昂、難以實現(xiàn),還容易導致過擬合,削弱模型的泛化能力,嚴重時甚至會引發(fā)災(zāi)難性遺忘。為解決這些問題,因此需要一種高效且靈活的解決方案來微調(diào)預訓練的文本到圖像模型,以便在保持泛化能力的同時,能夠應(yīng)對多樣化的下游任務(wù)需求。而適配器微調(diào)作為一種通過在預訓練模型中引入少量額外參數(shù)來實現(xiàn)高效微調(diào)的輕量級方案,正好能夠有效解決這些問題。
主要內(nèi)容:
本文設(shè)計了一個基于加性注意力的圖像融合模塊(IFM),該模塊能夠以非配對的方式同時注入兩張圖像提示進行訓練,增強了模型對圖像提示特征信息的提取能力。此外,在實驗中發(fā)現(xiàn),利用穩(wěn)定擴散模型中U-Net網(wǎng)絡(luò)的跳躍連接能有效傳遞圖像提示信息到U-Net網(wǎng)絡(luò)的上采樣塊。因此,本文僅在U-Net網(wǎng)絡(luò)的下采樣塊中引入適配器,相比于在U-Net網(wǎng)絡(luò)的所有塊中添加適配器,不僅降低了適配器的參數(shù)量和模型推理過程中的計算量,而且消除了因上采樣塊適配器輸入多余的圖像提示而引入的干擾信息。如圖1所示,展示了本文基于適配器方法的模型總體框架。
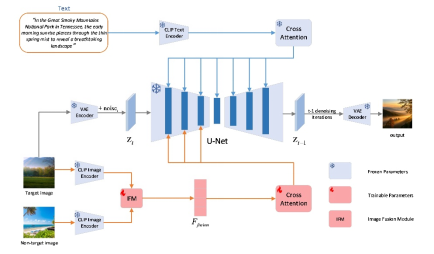
圖1 本文的模型總體框架
結(jié)論:
基于適配器法,本文首先設(shè)計了加性注意力圖像融合模塊,以支持同時注入兩張圖像提示來訓練,這增強了模型的特征提取能力;再利用U-Net的跳躍連接,僅在U-Net的下采樣塊引入適配器,減少了適配器的參數(shù)量與模型推理的計算量。實驗表明,該方法在保持適配器優(yōu)勢的基礎(chǔ)上提升了適配器的性能。
作者簡介:
劉建偉,教師。